训练集
数据集包含大量来自wikipedia的恶评,并且被分类为以下6个标签:
toxicsevere_toxicobscenethreatinsultidentity_hate- 创建一个模型来预测每个恶评在每种标签的可能性。
基本参数
MAX_SEQUENCE_LENGTH = 100
MAX_VOCAB_SIZE = 20000
EMBEDDING_DIM = 100 #embedding dimenstion
VALIDATION_SPLIT = 0.2
BATCH_SIZE = 128
EPOCHS = 10
读取golve做的词向量预训练的结果.word2vec 是通过glove预训练词向量构造的一个字典,每个单词都有一个对应的100维度的词向量,词向量来源于glove的预训练。
word2vec = {}
with open('D://software engineering/nlp_translate/glove.6B.100d.txt','r',encoding='utf-8') as f:
for line in f:
values = line.split()
word = values[0]
vec = np.asarray(values[1:], dtype='float32')
word2vec[word] = vec
print('Found %s word vectors.' % len(word2vec))使用keras库里的文本和序列预处理的库,Tokenizer是一个用于向量化文本,或将文本转换为序列的类。
train = pd.read_csv("D:/software engineering/nlp_translate/train.csv")
sentences =train["comment_text"].fillna("DUMMY_VALUE").values
possible_lables = ["toxic","severe_toxic","obscene","threat","insult","identity_hate"]
targets = train[possible_lables].values
print("max sequence length:",max(len(s) for s in sentences))
print("min sequence length:", min(len(s)for s in sentences))
s=sorted(len(s) for s in sentences)
print("median sequence length:", s[len(s)//2])
#convert the sentences into integers
tokenizer = Tokenizer(num_words = MAX_VOCAB_SIZE)
tokenizer.fit_on_texts(sentences)
sequences = tokenizer.texts_to_sequences(sentences)
word2idx = tokenizer.word_index
print('Found %s unique tokens.' %len(word2idx))
data = pad_sequences(sequences,maxlen = MAX_SEQUENCE_LENGTH)
print('Shape of data tensor:', data.shape)利用train中的comment_text数据,先造了一个字典word2idx,每个单词都有一个对应的下标序号,texts_to_sequences()的作用则是构造了一个list,list的数字来源于word_index这个字典。
如:单词nonsense,word2idx.get("nonsense")就是等于845。
pad_seq则是在sequences的基础上进行了填充,填充至100,这样每个sequences的维度就一样了。
构造一个embedding_matrix,只取了排名靠前的2W单词,并且把词向量填充进embedding_matrix。
num_words = min(MAX_VOCAB_SIZE, len(word2idx) + 1)
embedding_matrix = np.zeros((num_words, EMBEDDING_DIM))
for word, i in word2idx.items():
if i < MAX_VOCAB_SIZE:
embedding_vector = word2vec.get(word)
if embedding_vector is not None:
# words not found in embedding index will be all zeros.
embedding_matrix[i] = embedding_vector
将这个词向量矩阵加载到Embedding层中,设置trainable=False使得这个编码层不可再训练。如果输入数据不需要词的语义特征,简单使用Embedding层就可以得到一个对应的词向量矩阵,但如果需要语义特征,就需要把glove预训练好的词向量扔到Embedding层中。
embedding_layer = Embedding(
num_words,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False
)构造训练模型:
input_ = Input(shape=(MAX_SEQUENCE_LENGTH,))
x = embedding_layer(input_)
x = Conv1D(128, 3, activation='relu')(x)
x = MaxPooling1D(3)(x)
x = Conv1D(128, 3, activation='relu')(x)
x = MaxPooling1D(3)(x)
x = Conv1D(128, 3, activation='relu')(x)
x = GlobalMaxPooling1D()(x)
x = Dense(128, activation='relu')(x)
output = Dense(len(possible_lables), activation='sigmoid')(x)
model = Model(input_, output)
model.compile(loss='binary_crossentropy',optimizer='rmsprop',metrics=['accuracy'])
print('Training model...')
r = model.fit(data,targets,batch_size=BATCH_SIZE,epochs=EPOCHS,validation_split=VALIDATION_SPLIT)结果
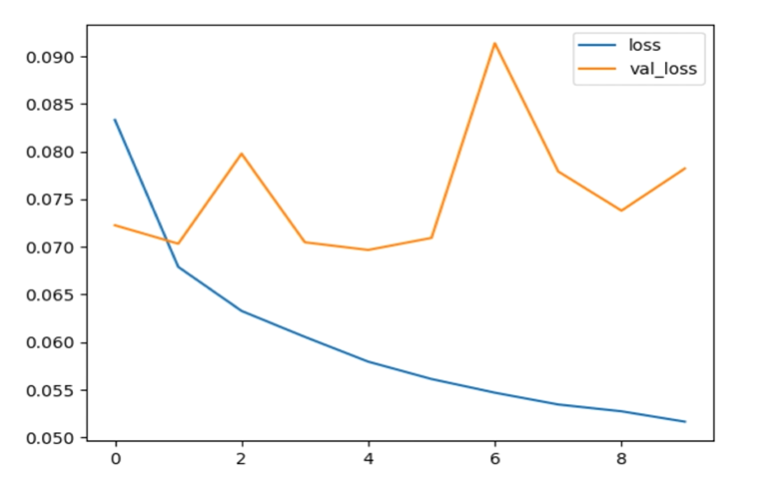
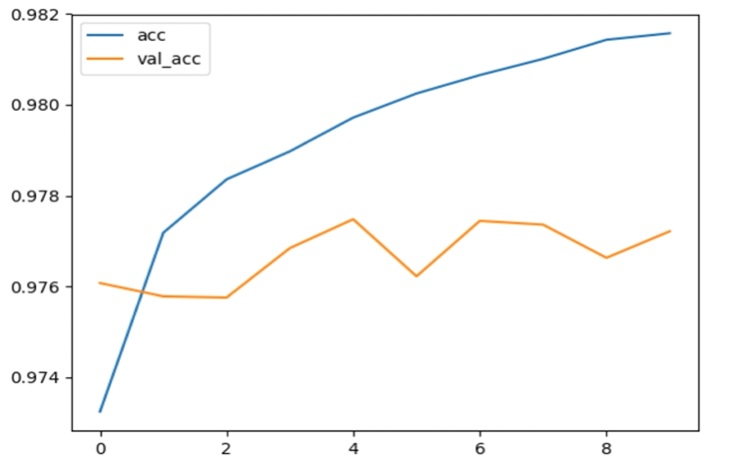
代码地址:https://github.com/Dennis174698/toxic

