Word2Vec是使用浅层神经网络学习词嵌入的最流行技术之一。它是由Tomas Mikolov于2013年在Google上开发的。
当使用one-hot 编码并将其可视化时,将其想象为一个多维空间,其中每个单词占据一个维,而与其余单词无关(沿着其他维没有投影)。这意味着词与词之间没有任何关联性,这是不正确的。我们的目标是使上下文相似的单词占据紧密的空间位置。在数学上,此类向量之间的角度的余弦值应接近1,即角度应接近0。
为此引入了一个单词对其他单词的某种依赖性。在该词的上下文中的词将在这种依赖性中获得更大的份额。Word2Vec是一种构造此类嵌入的方法,有两种方法(都涉及神经网络)来获得它:CBOW(Commom Bag of Words) 和 skipgram
CBOW:
此方法将每个单词的上下文作为输入,并尝试预测与上下文相对应的单词。考虑我以下例子:Have a great day
将 great 作为input 输入到神经网络。使用单个上下文输入单词great预测目标单词 day。更具体地说,使用输入字词的 one-hot coding,并与目标字词的 one-hot coding 相比,测量输出误差。在预测目标词的过程中,学习目标词的向量表示。
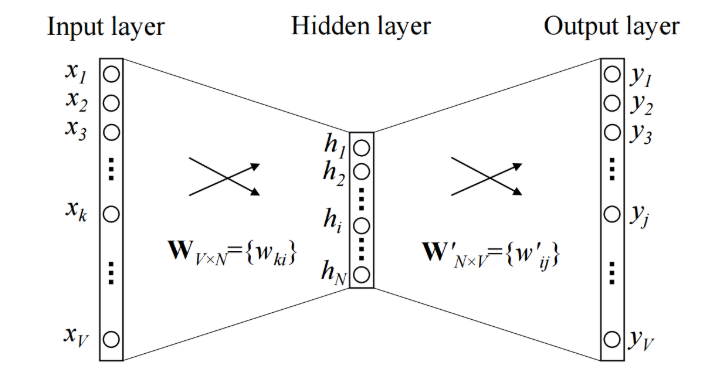
输入词是一个大小为V的热编码矢量。隐藏层包含N个神经元,输出是V长度矢量,其元素为softmax值。Wvn是将输入x映射到隐藏层的权重矩阵(V * N维矩阵).Wnv是将隐藏层输出映射到最终输出层的权重矩阵(N * V维矩阵)。隐藏层神经元仅将输入的加权总和复制到下一层。没有像sigmoid,tanh或ReLU这样的激活函数。唯一的非线性是输出层中的softmax计算。以上模型使用单个词来预测目标。也可以使用多个词来做同样的事情。
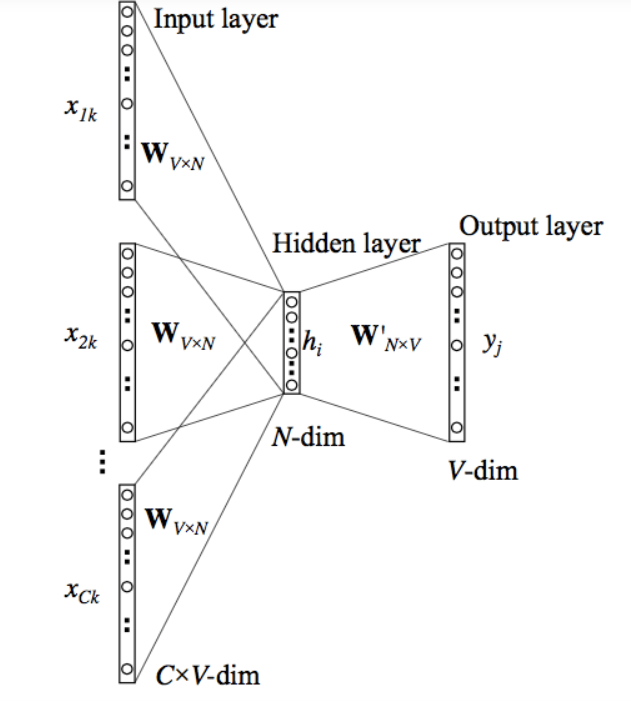
上面的模型采用C个词。当Wvn用于计算隐藏层输入时,我们对所有这些C上下文词输入取平均值。
还有另一种方法可以做到这一点。我们可以使用目标词(我们要生成其表示形式)来预测上下文,并在此过程中生成表示形式。
Skip Gram
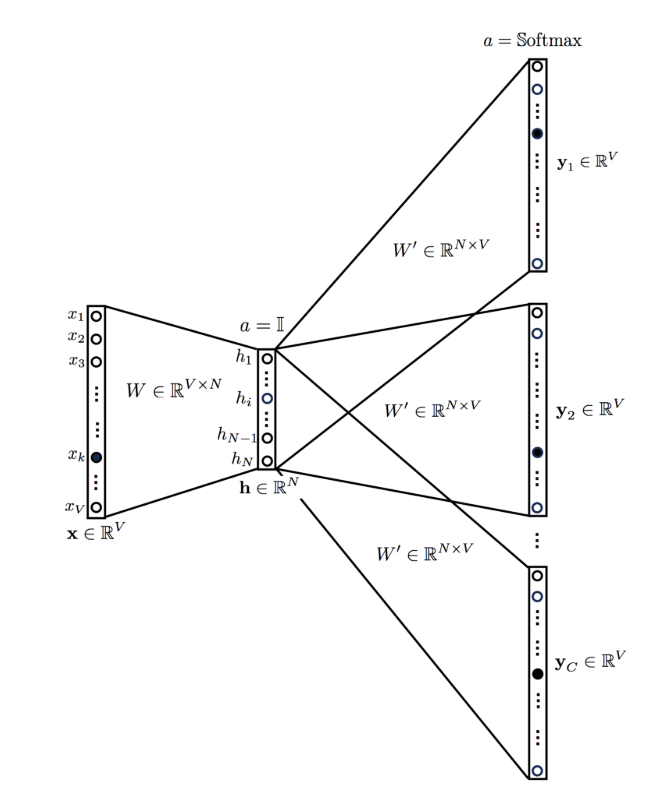
将目标词输入网络。该模型输出C个概率分布。
对于每个context 位置,我们获得V个概率的C个概率分布,每个单词一个。
在这两种模型下,网络都使用反向传播进行学习。

